검색엔진 최적화(SEO, Search Engine Optimization)란 구글 등과 같은 검색엔진의 검색 결과에 상위 랭크되어 보다 많은 사람들이 여러분의 웹사이트를 방문하게 만드는 것에서 부터 시작합니다. 그러다보니 검색엔진최적화를 위해서는 검색엔진이 우리의 웹사이트를 쉽게 찾아 크롤링하고 색인할 수 있게 해줘야 하고, 이를 위해서 검색엔진에게 몇가지 가이드 및 힌트를 제공하면 좋습니다. 이번 포스팅에서는 테크니컬 SEO의 기본적인 부분인 robots.txt와 sitemap.xml에 대해 알아보고자 합니다.

1. robots.txt 이란?
robots.txt 는 웹사이트에 대한 검색엔진 로봇들의 접근을 조절해주고 제어해주는 역할, 그리고 로봇들에게 웹사이트의 사이트맵이 어디 있는지 알려주는 역할을 합니다. 주의하실 점은 여기서 말하는 사이트 맵은 수집 로봇을 위한 XML 사이트 맵을 말하며, 웹사이트의 메뉴 전체를 보여주는 사이트 맵을 의마하는 것은 아닙니다.
robots.txt 파일을 설정하지 않으면 구글, 네이버 등 각종 검색엔진 로봇들이 웹사이트에서 찾을 수 있는 모든 정보를 크롤링하여 검색엔진 검색결과에 노출시킵니다. 만약 웹사이트 내 특정 페이지가 검색엔진에 노출되지 않기를 바란다면 robots.txt파일을 설정하여 이를 제어할 수 있습니다.

1.1 robots.txt는 어떻게 설정할까?
robots.txt는 html이 아닌 일반 텍스트파일로 작성하며 사이트의 루트 디렉토리에 위치해야 합니다. 다른 곳에 robots.txt를 올리면 검색 로봇이 찾을 수 없습니다. robots.txt은 누구에게나 공개된 파일로 여러분이 알고 있는 웹사이트 URL 뒤에 /robots.txt 를 입력하면 다른 웹사이트는 어떻게 robots.txt 파일을 적용시키고 있는지 확인할 수 있습니다.
User-agent: *
Disallow: /
위와 같이 robots.txt를 설정하면 모든 웹사이트 콘텐츠에 대한 모든 웹 크롤러의 접근을 차단함을 의미합니다. 만약 구글 로봇만 차단시키고 싶다면 User-agent에 * 부분을 Googlebot으로 변경하여 설정할 수 있습니다. 그렇지만 웹사이트의 모든 콘텐츠를 차단시킨다면 검색엔진최적화에 매우 좋지 않은 영향을 끼치겠죠? 많은 사람들은 가능한 한 모든 콘텐츠를 허용하되 몇가지 콘텐츠만 차단하기를 원할 것입니다.
User-agent: Yeti
Disallow: /hello/
이렇게 설정하면 웹사이트의 모든 콘텐츠의 네이버 검색로봇의 크롤링을 허용하되, /hello/ 디렉토리 안의 페이지에 대한 접근만 차단한다는 의미입니다. 검색엔진별 검색 로봇의 이름은 모두 상이합니다. 자주 쓰이는 검색로봇의 이름은 구글 (Googlebot), 네이버 (Yeti), 빙 (Bingbot), 야후 (Slurp) 등이 있습니다.
1.2. robots.txt가 검색엔진최적화에 주는 영향은?
robots.txt는 언뜻보면 웹크롤러의 접근을 막아주는 역할을 하기 때문에 robots.txt를 설정하는 것이 어떤 면에서 검색엔진최적화에 도움을 주는지 이해하기 어렵습니다. 그렇지만 검색엔진최적화 전문가들은 테크니컬 SEO를 진행할 때 항상 robots.txt파일을 설정하는 것을 권장합니다.
설정이 도움이 되는 구체적인 예를 들어보겠습니다. 웹사이트 내에 똑같은 콘텐츠를 가진 웹페이지가 여러개 있고, 만약 웹크롤러가 이 모든 페이지를 읽어간다면 이는 웹사이트 검색엔진최적화에 부정적인 영향을 줍니다. 특히 구글은 중복콘텐츠에 대해 페널티를 주기도 하기 때문에 만약 웹사이트 내 중복 콘텐츠가 있을 경우 robots.txt를 통해 적절히 제어해주는 것이 검색엔진최적화에 도움을 줄 것입니다.
또한 robots.txt는 웹사이트의 사이트맵 위치를 포함하기 때문에 검색 엔진 로봇들에게 어디에서 웹사이트 정보를 가져가야 할 지 알려주는 역할을 합니다. 물론 요즘은 각 검색엔진의 웹 마스터툴 (구글 서치 콘솔, 네이버 서치 어드바이저) 을 이용해 사이트맵을 제출할 수 있지만, 따로 웹마스터툴을 이용하지 않는 경우는 robots.txt에 사이트맵 주소 한 줄만 포함하는 것으로도 검색 로봇들에게 사이트맵 정보를 전달할 수 있습니다.
2. sitemap.xml 이란?
sitemap.xml은 웹사이트 내 모든 페이지의 목록을 나열한 파일로 책의 목차와 같은 역할을 합니다. 사이트맵을 제출하면 일반적인 크롤링 과정에서 쉽게 발견되지 않는 웹페이지도 문제없이 크롤링되고 색인될 수 있게 해줍니다.
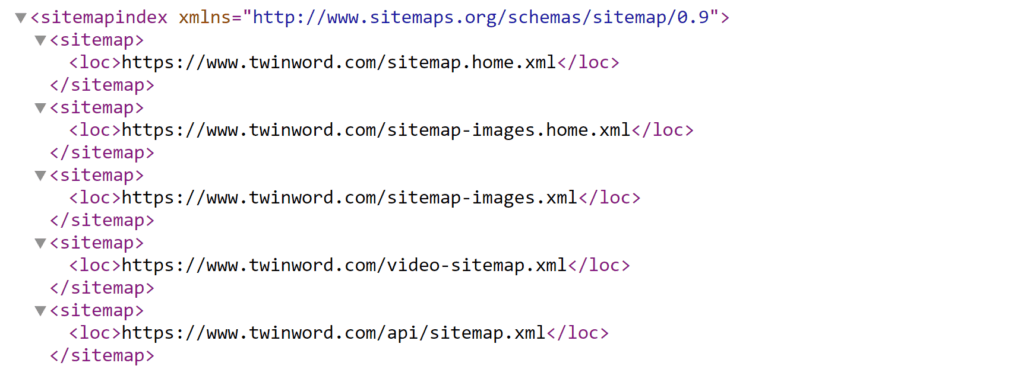
2.1. sitemap.xml은 어떻게 설정할까?
robots.txt 파일과는 달리 sitemap.xml 파일은 꼭 루트 디렉토리에 위치하지 않아도 됩니다. 그렇지만 많은 웹사이트들은 sitemap.xml 파일도 robots.txt와 마찬가지로 루트 폴더에 업로드하기 때문에, 다른 웹사이트의 sitemap.xml을 참고하고 싶다면 웹사이트 URL 뒤에 /sitemap.xml 을 입력하여 찾아볼 수 있습니다.
sitemap.xml은 정해진 양식으로 제작되어야 하고, 이 양식은 전 세계적으로 약속된 방식입니다. Sitemap.org 사이트를 방문해보면 sitemap.xml에 관한 샘플 포맷, xml 태그에 대한 자세한 설명을 읽어 볼 수 있습니다. 최근에는 사이트맵을 무료로 생성해주는 온라인 사이트들도 많기 때문에 원한다면 이러한 사이트를 활용하여 빠르게 sitemap을 제작할 수도 있습니다. (관련 글: 사이트맵을 쉽게 만드는 3가지 방법과 제출하는 방법)
2.2. sitemap.xml이 검색엔진최적화에 주는 영향은?
sitemap.xml도 robots.txt와 마찬가지로 파일을 생성했다고 해서 웹사이트 검색엔진최적화 점수를 높이는데 영향을 주는 것은 아닙니다. 다만 앞에 언급된 바와 같이 검색 엔진 로봇의 일반적인 크롤링 과정에서 발견되지 않는 웹페이지에 대한 정보를 제공해주기 때문에 더 많은 웹페이지가 크롤링되고 색인될 수 있게 도와주므로, 넓은 의미에서 sitemap.xml을 설정하는 것은 검색엔진최적화에 긍정적인 영향을 끼칩니다.
3. robots.txt 와 sitemap.xml 관련 제한 사항
robots.txt 에는 얼마나 많은 사이트맵 파일을 지정할 수 있을까요? 파일 개수가 정해져 있지는 않으며, 여러 개의 사이트맵 또는 사이트맵 인덱스 파일을 지정할 수 있습니다. 다만, 구글에 의하면 robots.txt 파일이 500 KB 가 넘지 않아야 한다고 권고하고 있습니다.
한편 사이트맵 인덱스 파일에 여러 개의 사이트맵 파일을 포함할 수 있습니다. 하나의 사이트맵 인덱스 파일에는 최대 50,000 개의 사이트맵을 지정할 수 있으나, 압축 전 크기가 50 MB 를 넘지 않아야 합니다.
아울러 하나의 사이트맵 파일에는 최대 50,000 개의 웹 페이지 주소를 지정할 수 있습니다. 단 압축 전 크기가 10 MB 를 넘지 않아야 합니다.
제한 사항 관련하여 마지막으로 알아 두면 좋은 내용은 구글의 경우 사이트맵 인덱스 파일이 다른 사이트맵 인덱스 파일을 포함할 경우 에러를 낸다는 사실입니다.
이러한 robots.txt 와 sitemap.xml 파일 관련 제한 사항을 지키면서 많은 개수의 웹페이지 주소를 지정하여 색인해야하는 상황이라면 아래와 같은 방향을 권장합니다.
- robots.txt 파일에는 사이트맵 또는 사이트맵 인덱스 파일을 수십 개 정도 두는 것이 전혀 문제가 되지 않으므로, 적당한 개수를 자동과 수동 등 생성 시기와 콘텐츠 구분에 따라 필요한 만큼 정의합니다.
- 사이트맵 인덱스 파일과 사이트맵 파일에는 각각 최대 50,000 개의 다른 사이트맵 또는 페이지 주소를 포함할 수 있으나, 파일 크기 제한 등을 고려할 때, 10,000 개를 넘지 않도록 관련하는 편이 좋겠습니다.
- 만약 robots.txt 파일에 3 개의 사이트맵 인덱스 파일을 지정하고 10,000 개의 사이트맵과 10,000 개의 주소를 지정한다고 하면, 3 x 10,000 x 10,000 = 3 억 개의 웹페이지 색인용 주소를 지정할 수 있습니다.
4. 검색엔진별 수집 로봇 정보
많은 검색 수집 로봇이 있으며, 각 검색 로봇은 수집을 시작할 때 자신이 수집 로봇이라는 정보를 서버에 보내줍니다. 아래 리스트는 각 검색엔진별 로봇에 대한 정보를 담고 있는 페이지이며, 수집 로봇을 제한하거나 확인할 때 참고하면 좋습니다.
- [Google]
https://support.google.com/webmasters/answer/80553?hl=en - [Bing]
http://www.bing.com/webmaster/help/how-to-verify-bingbot-3905dc26 - [Yahoo]
http://www.ysearchblog.com/2007/06/05/yahoo-search-crawler-slurp-has-a-new-address-and-signature-card/ - [Naver]
https://searchadvisor.naver.com/guide/seo-basic-firewall - [Daum]
https://cs.daum.net/m/faq/faqlist/36378 - [Yandex]
https://yandex.com/support/webmaster/robot-workings/check-yandex-robots.html - [Baidu]
https://help.baidu.com/question?prod_id=99&class=0&id=3001
검색엔진최적화(SEO)를 제대로 하고 싶다면 robots.txt와 sitemap.xml과 같은 테크니컬 SEO의 기초를 다진 후, 콘텐츠 SEO에 집중하는 것이 웹사이트 트래픽 유입을 증진시키는데 효과적입니다. 훌륭한 콘텐츠를 제작해놓고 robots.txt 파일을 잘못 설정하여 웹 크롤러가 크롤링을 해가지 못하는 것만큼 아쉬운 일은 없을 것입니다.
한편 robots.txt와 sitemap.xml 이외에도 구글 SEO를 위해서 꼭 알아야 할 테크니컬 SEO 요소가 여러가지 있습니다. 구글 검색엔진최적화 방법을 정리한 글을 읽어보며 여러분의 SEO 성과를 높여보세요!


{kind=link}
{kind=link}
{kind=link}
10 Comments
좋은정보 감사합니다.
도움이 되었다니 다행입니다. 감사합니다.
빠른 답변 감사드립니다!!! 큰 도움이 되었습니다.
포스팅 잘 봤습니다 🙂 감사합니다!
질문이 있는데요, blog.naver.com/robots.txt를 보니 상단에
User-agent: Yeti
Disallow: /
라고 되어있고 하단에 별도로 접근설정이 되어있더라고요. 그런데 이게 Yeti의 크롤링을 차단하는 거잖아요..?
이부분이 이해가 잘 안되서요… 괜찮으시다면 답변 부탁드립니다!
검색 로봇에 의한 수집이 불필요한 경우로 보여집니다. Yeti 의 경우 네이버 검색 로봇이다보니, 네이버가 자체적으e로 blog.naver.com 의 문서를 색인하기 때문에 중복해서 네이버 검색 로봇(Yeti) 에 의한 색인을 할 필요는 없을 것입니다.
유익한 내용 감사합니다. 사랑합니다❤️
정말 잘 보고 갑니다~
잘 봤습니다. 유용한 정보 감사합니다.
정말 큰 도움 되었습니다!! 감사합니다^^
도움이 되었다니 다행입니다. 🙂